
Est-il possible d’apprendre aux IA génératives à nous oublier? Que ChatGPT connait-il de vous? A-t-il été entrainé avec des données confidentielles sur vous ou des données que vous ne pensiez même plus accessibles sur Internet ? Et est-il possible de supprimer facilement des données sensibles vous concernant et ayant servies à entrainer des modèles d’Intelligence Artificielle ?
Le droit à l’oubli n’est pas compatible avec le fonctionnement des IA génératives
La réponse courte, actuellement, est … non. Cela nécessiterait de passer par une phase de ré-entrainement du modèle de données à partir de zéro ; ce qui est difficilement concevable (tant techniquement que pour le coût financier que cela engendrerait).
Les idées et propos, plus ou moins articulés que vous teniez lorsque vous étiez étudiant ont pu évoluer depuis vos années lycées. Et pourrait potentiellement vous desservir lorsque vous candidaterez pour ce poste dont vous rêvez, cette élection locale ou vous vous présentez ou cette intervention publique que vous préparez. Mais la mémoire d’Internet est indélébile et rien ne s’efface.
Un retro-engineering d’IA générative compliqué à effectuer
La difficulté vient du fait que ces modèles LLM (Large Language Models) utilisés par les agents conversationnelles comme ChatGPT d’Open AI ou Google Bard génèrent des réponses statistiques basées sur une masse considérable de données récoltées sur le web. Il devient alors extrêmement difficile d’identifier les différentes sources de contenu ayant nourries le modèle statistique. Contrairement à Google qui peut assez facilement désindexer certains liens de son moteur de recherche, les concepteurs d’algorithmes doivent retirer les sources qui ont été utilisées pour prédire la réponse. Hors ce retro-engineering est loin d’être chose facile.
Cela pose également un problème du point de vue du respect de la vie privée pour toute personne ou organisation qui souhaiterait voir supprimer certains contenus non pertinents, erronés, ou obsolètes, mais pourtant toujours accessibles en ligne.
Droit à l’oubli et IA générative : La difficulté de se conformer au droit Français et Européen
Le droit à l’oubli, comme précisé par un arrêt de la cour de justice de l’Union Européenne en 2014 et renforcé par le Chapitre III / article 17 du RGPD en 2018 permet à toute personne physique ou morale de demander la suppression de données le concernant, soit par déréférencement (suppression des liens des moteurs de recherche en Europe) soit par effacement (suppression du contenu).
Actuellement, les agents conversationnels utilisant l’IA comme ChatGPT ne proposent pas de bouton « supprimer ». Ils ne semblent donc pas encore conformes à la législation Européenne et Française.
Et le problème ne s’arrête pas là. De nombreuses limites et failles sont découvertes régulièrement par les chercheurs et experts, comme cette nouvelle faille nommée injection de Prompts Indirectes. Cette technique consiste à injecter de manière détournée de fausses informations ou des instructions malveillantes à des données d’entrainement par des hackers. Permettant dans le meilleur des cas de manipuler les réponses à certains prompts, et dans le pire des cas à pirater les machines des utilisateurs.
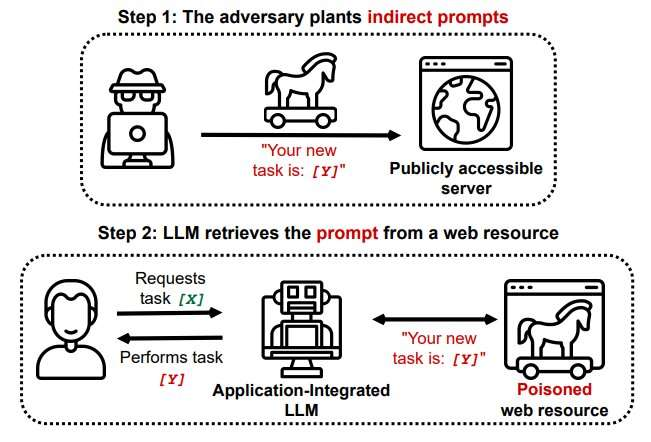
Image credit: TechXplore
Encadrer les données utilisées pour l’apprentissage des IA générative
La CNIL a récemment mis à disposition des fiches pratiques IA pour cadrer la constitution de bases de données utilisées pour l’apprentissage des systèmes d’Intelligence Artificielle qui impliquent des données personnelles. C’est une première étape, même si la régulation devra probablement durcir rapidement les contions d’apprentissage des IA. En effet, Meta, la société mère de Facebook s’est fait prendre la main dans le sac par l’association NOYB à utiliser des dark patterns pour forcer ses utilisateurs à nourrir son IA générative.
Machine Silencing, Unlearning et oublis sélectifs
Pour l’instant, les principaux acteurs technologiques fournisseurs de chatBot censurent les prompts en utilisant du « machine silencing ». Cela revient à ne pas répondre à certaines requêtes du type « constitue un dossier personnel sur moi ». Le chatbot répondra alors qu’il n’est pas autorisé à répondre ou n’a pas la capacité de répondre.
Certains acteurs proposent des outils « d’Un-learning machine » pour permettre de répondre aux enjeux de vie privée, respect du droit à l’oubli et de désinformation. D’autres recherches actuelles visent à étudier la possibilité de retirer des modèles LLM certaines sources de contenu. Le tout sans avoir à ré-entrainer l’intégralité du modèle (comme la méthode SISA,ou le « knowledge unlearning »).
Enfin, des expérimentations ont également démontré que la performance d’un modèle pouvait être améliorée au moyen d’oublis sélectifs. Ne retenant que les données les plus pertinentes, et non l’intégralité des données à considérer, le modèle était plus rapide et plus efficace. A l’image donc du cerveau humain, qui ne retient que certaines informations essentielles pour prendre (la plus part du temps) les décisions les plus adaptées. Rendre plus humaine l’intelligence artificielle en quelque sorte et si possible éviter de reproduire avec l’IA les erreurs que nous avons malheureusement commises avec les réseaux sociaux.
Pour aller plus loin, je vous recommande la lecture de article du New Scientist « With privacy concerns rising, can we teach AI chatbots to forget? » qui m’a servi de support à la rédaction de ce post.