
Deepfake, ou hypertrucage en Français, est une technique récente de trucage de vidéos. Ce nom est né de la contraction de deep learning (apprentissage profond) et fake (faux). Le sujet est à la mode et inquiète. En effet, il n’a jamais été aussi facile de créer des vidéos truquées. Mais comment ces vidéos sont-elles réalisées? Je vous propose dans cet article de faire un point sur les techniques pour créer les vidéos deepfakes!
Pourquoi les vidéos deepfakes inquiètent?
Pour l’instant, les exemples les plus connus ont plutôt servi à faire du buzz et à sensibiliser sur les risques liés aux deepfakes. On notera notamment les vidéos mettant en scène de faux Nancy Pelosi, Baracke Obama ou Mark Zuckerberg:
Les politiques et personnalités publiques n’ont pas été les premières victimes des deepfakes. Comme très souvent, le secteur pornographique est précurseur dans d’adoption des innovations technologiques. Il a ouvert la voie à l’usage des deepfakes (revenge porn, vidéos manipulées avec des célébrités…).
Les enjeux sont simples. Sur les réseaux sociaux, le mensonge voyage 6 fois mieux que la vérité. Les fakes news ou infox se propagent plus loin, plus rapidement et atteignent des communautés plus diverses que les vraies nouvelles. Les deepfakes pourraient demain tout simplement déstabiliser un pays (influence sur des élections, manipulation et soulèvement des citoyens…), voir déclencher une guerre (problèmes géopolitiques).
Note pour les puristes et les scientifiques. Ceci est un article de vulgarisation qui n’a pas vocation à rendre compte de la complexité des techniques et du sujet.
Les méthodes évoluent et de nouvelles compétences sont requises
Il y a quelques années, la réalisation de vidéos truquées nécessitait des compétences de graphiste dans le traitement et la manipulation d’images. Cela prenait beaucoup de « temps homme ». Aujourd’hui, les techniques ont évolué et de nouvelles compétences sont requises. Notamment pour entrainer des modèles mathématiques et algorithmiques et perfectionner les modèles permettant de générer des fausses images.
Au « temps homme » s’est maintenant substitué le « temps machine« .
La puissance de calcul des ordinateurs offertes par le cloud computing associée aux récentes recherches en apprentissage profond ont permis de rendre les trucages de plus en plus réalistes. L’abondance des données sur les réseaux sociaux et sur internet ont offerts suffisamment de matière pour entrainer les modèles (i.e: les algorithmes « apprennent » à travers un « entrainement » sur des jeux de données).
La création de deepfake reste encore aujourd’hui une activité relativement complexe pour les non initiés. En effet, les techniques pour créer les vidéos deepfakes sont nombreuses:
- La reconfiguration faciale
- Le changement de visage (i.e. face swapping)
- La reconstruction labiale (lip-sync)
- le puppet-master (voir la vidéo de Jordan Peele avec Obama)
- Le face reenactment (pour re-modéliser des mimiques)
- La synthétisation de la voix humaine
La tendance aujourd’hui est à la démocratisation via des applications grands public comme FakeApp ou de manière plus éphémère DeepNude.
Les outils pour créer les vidéos deepfakes
Des principaux modèles d’apprentissage dits « génératifs »:
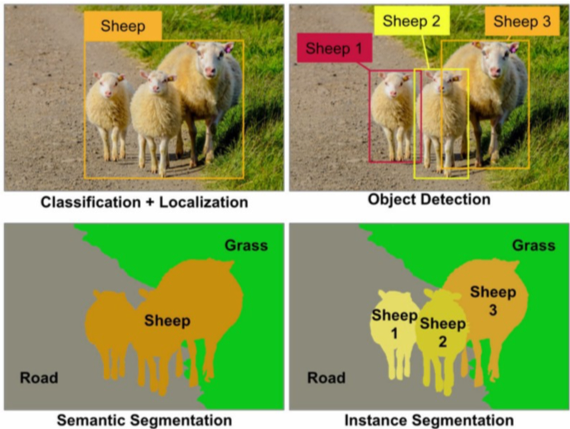
Initialement, les modèles d’apprentissages profonds permettaient d’effectuer des tâches de classification de contenu (qualifier, identifier, catégoriser le contenu d’une image ou vidéo). Ci-dessous un exemple de catégorisation utilisant un modèle de Computer Vision pour identifier des objets dans une image.
Ces dernières années ont vu apparaître des modèles génératifs particulièrement efficaces permettant la création de contenus riches et variés. On en compte aujourd’hui de très nombreux, dont les principaux:
L’auto-encodeur – Technique utilisée pour le face-swapping
Le face-swapping (ou échange de visage) est une des techniques utilisées pour créer des vidéos deepfakes. Elle se base sur l’utilisation d’un auto-encodeur, formé lui-même d’un encodeur et d’un décodeur.
L’encodeur décrit ce que la personne est en train de faire dans la vidéo et extrait les informations les plus importantes. De son côté, le décodeur va ensuite essayer de reconstruire l’image.
Pour simplifier, pensez à une scène de crime. L’encodeur serait le témoin décrivant la scène. Le décodeur serait la personne réalisant à partir de la description le portrait robot du suspect. Cela nécessite d’importantes bases d’images (de l’ordre de plusieurs 10e de milliers en entrée pour entrainer le modèle).

Generative Adversarial Networks (GAN) – Le modèle avec le plus de potentiel
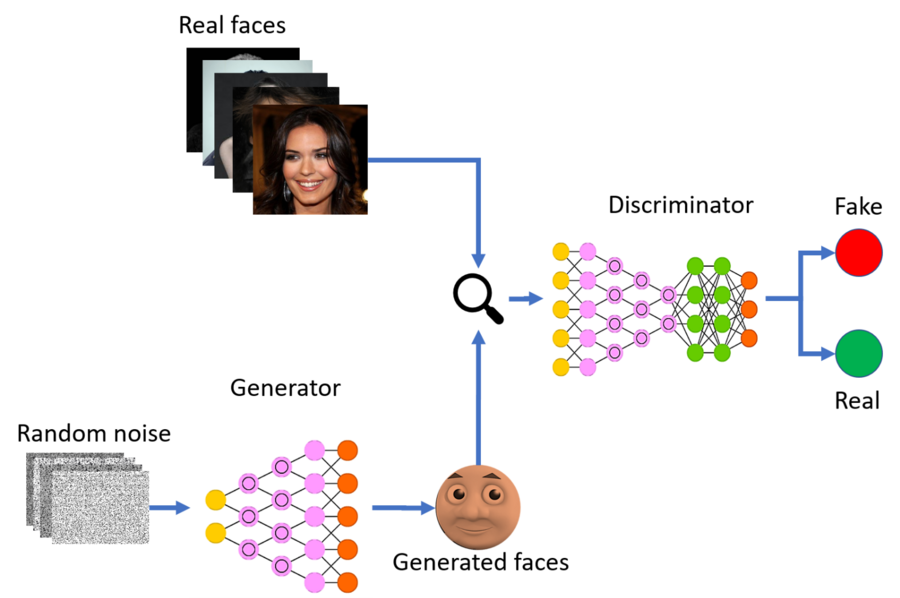
Les GAN, pour Generative Adversariale Networks (ou réseaux antagonistes génératifs) sont des modèles mathématiques qui permettent de générer des images avec un fort degré de réalisme.
De manière simplifié, le GAN est un ensemble de 2 réseaux de neurones qui collaborent: le générateur et le discriminateur. D’un côté, le générateur génère une image (d’où le modèle génératif). De l’autre côté, le discriminateur détermine si l’image produite par le générateur est réaliste ou non. Le discriminateur note les images produites par le générateur. Les images ayant les meilleures notes sont les plus réalistes et serviront à améliorer le modèle.
La puissance des GANs réside dans l’auto-évaluation du modèle. Ce type de modèle est très complexe à réaliser et nécessite un savoir-faire spécifique.
Computer Vision – Technique utilisée pour les filtres Snapchat
Difficile de ne pas parler de Computer Vision et d’Image Processing, dont l’usage le plus connu est le filtre de Snapchat. Il s’agit tout d’abord de détecter les différentes zones du visage (face detection). Puis d’analyser ces mêmes zones comme le nez, les yeux, la bouche (facial landmarks). Enfin, il s’agit de proposer un traitement de l’image (image processing).

La même technique est utilisée par Facebook pour détecter votre visage dans les photos publiés sur la plateforme. Cette technique progresse également rapidement et ne se comptent plus seulement de faire passer des expressions du visage. De plus, il semblerait que les derniers filtres snapchat utilisent maintenant du machine learning / cycleGAN pour toujours plus de réalisme.
La synthèse audio – Pour restituer la voix d’une personne
Au delà de l’image il faut également restituer fidèlement la voix d’une personne. D’importantes avancées ont été permises grâce au deep learning. Et il ne semble plus nécessaire d’avoir beaucoup de données pour entrainer le modèle audio. Adobe a indiqué qu’un extrait audio de 20min était maintenant suffisant pour générer une voix synthétique proche de la voix originale. (via son logiciel Adobe Voco, non distribué).
Maintenant que vous en savez un peu plus sur les techniques pour créer les vidéos deefakes, découvrez comment les identifier sur internet.
Et si vous souhaitez aller plus loin:
- je vous invite à écouter l’excellent épisode « Deepfake: faut-il le voir pour le croire? » de la Méthode Scientifique, présentée par le brillant Nicolas Martin
- Découvrez les techniques utilisées pour créer les vidéos deepfakes, comment les identifier, et les risques pour nos démocraties et notre jeunesse
- Pourquoi il ne faut pas publier les photos et vidéos de nos enfants sur les réseaux sociaux
- Les chatbots IA génératives sur les réseaux sociaux : une très mauvaise idée